
データ、情報、知識、インサイト(洞察)の違い
- データ(Data)
- 情報(Information)
- 知識(Knowledge)
- 洞察(Insight)
データは、事実や数字のことである。ただし、それがそこにあるだけでは情報にはならない。
情報とは、データが処理・加工され、分析され、解釈し、構造化し、有意義でかつ利用価値を持つような意味を持たせて他の第三者に報告されるものである。
知識とは、論理的または実用的(実際的)な物事への理解である。情報を経験や学習により知識として用いることができる。
洞察(インサイト)とは、複雑な状況をより深くより明確に理解できることである。この理解は、認知力や直観力から得ることができる。そして、洞察は、将来の採るべき最善策を得るためのものである。
データアナリティクスを進めるステップ
意思決定のために強力で役に立つ洞察(インサイト)を得るためにデータを集め、情報に加工し、知識として活用する。そのためのプロセスは以下の4ステップからなる。
- 記述的分析(Descriptive analytics)
- まずは過去実績をあるがまま描画できるようにする。何が起こったのか?(What happened?)という問いに答えられるようにする。
- 診断的分析(Diagnostic analytics)
- 次に、なぜそういう事実が発生したのか、過去業績がそうであった理由は何か?(Why did it happen?)という問いに答えられるようにする。
- 予測的分析(Predictive analytics)
- そして、相関分析により、将来に起こりそうなことは何か?(What is likely to happen?)という問いに答えられるようにする。
- 大量の過去データから法則やアルゴリズムを用いて、将来起こり得るパターンやトレンドを見つける。
- 指示的分析(Prescriptive analytics)
- 最後に、目標達成・目的の貫徹のために、最適手段は何か?(What needs to happen?)という問いに答えられるようにする。
- 将来予測を踏まえたうえで、自己や自組織にとって最適なリアクションや解決施策を探索する。
ビッグデータとは
とてつもない膨大な量のデータセットで、従来型のデータマネジメントシステムでは扱うことのできなかった種類のデータも含む。
コミュニケーションのデジタル化が進み、SNSなど、構造化データ以外のデータの増加量・増加速度がとてつもなく大きく速くなっていることから使われ始めるようになった。
- 構造化データ(Structured data)
- あらかじめ決められたフォーマットをもとに、そのような文字データ(data)をプログラムに理解できるよう構造化して(structured)記述したもの
- 簡単にいうと、列と行からなるフォーマットに即したもの
- 代表的なものに、リレーショナルデータベース(SQL言語)で操作・管理できるデータがある
- 非構造化データ(Unstructured data)
- 構造定義がなされておらず、リレーショナルデータベースでは操作・管理できないもの
- 電子メール、PDF、音声、画像、RFID、ドキュメント(契約書やスプレッドシート)
- 半構造化データ(Semi-structured data)
- カラム定義やテーブル定義のような明確な規定のデータモデルを参照していないもの
- JSON、XML、Parque、Avro等のデータフォーマットのもの。時には、CSV等、フラットファイル(フラットテーブル)形式も含む

ビッグデータの特徴
次の「v」から始まる言葉で語られることが多い。
- Volume(データ量)
- 人同士、プロセス同士、人とプロセスがデジタルでつながり、指数関数的にデータ量が増えていく
- Velocity(データの増加速度)
- 様々なデバイス(PC、スマートフォン、車載機器、スマート家電等)が相互にネット接続し、何が重要なデータか区別するのが難しくなるくらいのスピードでデータが増えていく
- Variety(データの多様性)
- データフォーマットの多様化。以前は正規化されたリレーショナルデータベースで保存できていたものが、現在では、画像、音声、動画、非構造化のままの大量のテキスト情報、ログ情報など、非互換性をもったままの各種フォーマットデータが溢れている
- Veracity(データの正確性)
- データアナリティクスの目的を達成するには、膨大な量のデータの中から、真実性・正確性を持ったデータを見つけなければならない
- 簡単にコピーやダウンロードができるため、品質チェック、バイアスで偏らない、不正、不完全なデータを分析対象から取り除く必要がある
- “Garbage in, garbage out”
- Variability(データの可変性)
- データフローは一定ではなく、季節変動があり、ピークや偏りがあり、首尾一貫していないかもしれない。また、様々な種類の疑問にデータアナリティクスで回答していこうとすると、様々な解釈をする必要も出てくる
- Value(データの価値)
- 解析したいデータは膨大に存在するが、データアナリティクスをする時間とコスト(人手)は有限である。
- 有用な意思決定のために、データアナリティクスを実行するわけだから、データアナリティクスにかけたコストを上回るベネフィットが得られるようにする必要がある

データマイニングとは
データマイニングとは、統計処理の技術によって膨大な量のデータセットから必要なデータだけを抽出し、これを分析することで意思決定に役立てることである。
データマイニングが発見する意思決定に有用なものとは、以前は不明だった事実、有用なデータパターン、データトレンド、データ間の相関関係などである。
SQLによるデータ処理はもとより、統計解析の技術、機械学習(machine learning)、AIなどの技術を活用する。
例えば、回帰分析による相関分析を行い、過去トレンドから将来の傾向や予測値そのものを明らかにすることで、将来の行動に関する意思決定を助ける。
それは、大量の過去データの中から一定のパターンや法則を見つけ出し、将来ケースにも当てはまるものを見つけることである(generalization)。
この手法は、「予測的分析(Predictive analytics)」に含められるものである。
データマイニングをする際に留意すべきこと
- データ品質
- データが間違っている、データが古い(更新されていない)、データに重複がある場合、そういうデータの分析結果から得られるベネフィットも小さくなる
- 複数のロケーション
- 同一のデータを複数の場所や、複数の担当者が扱うことで、異なるバージョンや、使用しているデータがそもそも別だったというコミュニケーションロスンロスが発生する
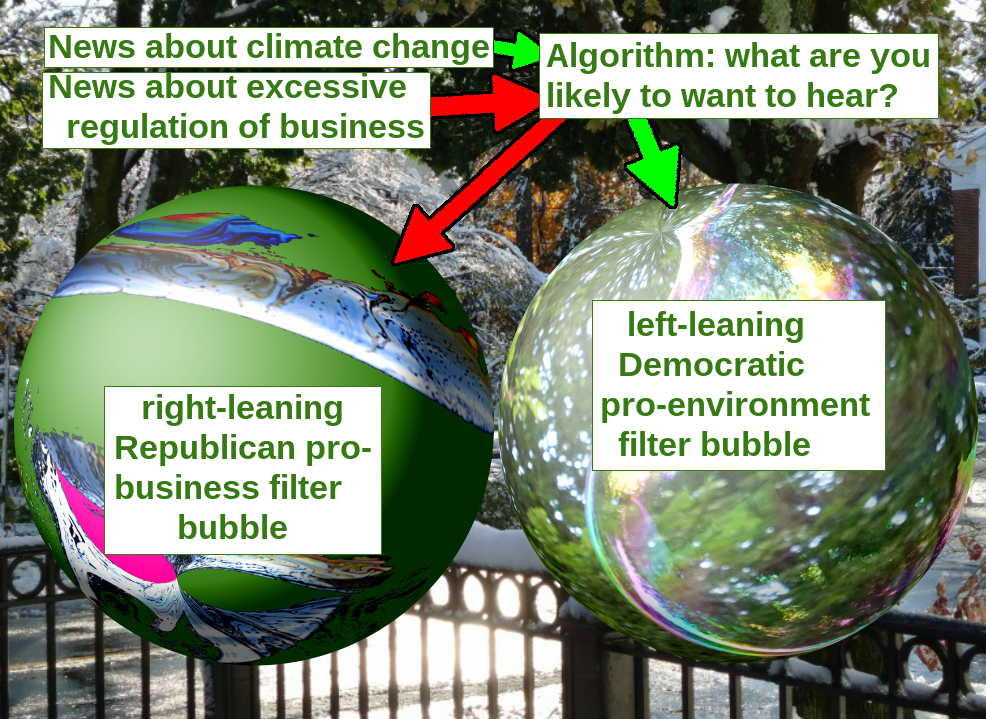
- バイアスの増幅
- フィルターバブル、エコーチェンバー現象
- 相関関係と因果関係の違い
- スタジオジブリ制作のアニメが日本でTV放映されると、米国の株価が下がるのは単なる「相関関係」
- テスト勉強したからテストの得点が上がったのは「因果関係」(注:交絡因子の存在など、実際には因果関係を証明することは非常に難しい)
- 倫理的な問題
- データ収集時のプライバシーの侵害など。民族、年齢、性別、学歴、収入などの個人情報
- データセキュリティ
- 特に個人情報など、ネット接続可能な環境におかれたデータが外部漏洩やハッキング対象にあったりする危険性
- 非構造化データへの対応
- 従来のリレーショナルデータベースでは取り扱うことのできないフォーマットのデータが増加することで、分析できなくならないように、専用のツールや分析環境を整備する
データマイニングの進め方
データマイニングは一般的には下記のようなステップで進められることが多い。
- 分析目的の明確化
- データの分析結果にユーザが本当に欲しいインサイトが何かを理解しておく
- 分析が1回限りなのか、継続的に行われるのかの想定を知る
- 使用するデータセットの選定
- データマイニングする対象のデータセットを分析目的に沿うように決める
- データセットの探索とクレンジング
- サンプルデータが有効範囲内に収まっており外れ値が無いか確認
- 空白値やデータ定義に反したものがないか確認
- 必要に応じてデータを修正
- 必要に応じて分析軸を減らす
- 分析に不要な軸・属性を無くす
- 場合によっては分析に必要な軸・属性を追加する
- データマイニングのタスクを決める
- 選別、予測、クラスタリングなど、データマイニングの手順を決める
- 上記1.の依頼者の目的・質問をデータマイニングの具体的な手法に落とす
- データ種別を仕切る
- 例えば、教師あり学習の分析をするなら、分析対象データは、training, validation, testing の3つに分ける
- データマイニングのどの技術を使うか決める
- 例えば、回帰分析、ニューラルネットワーク、層別クラスタリングなど
- アルゴリズムを実行する
- 可能なら、何回か試行して、チューニングする
- アルゴリズムが出した結論を解釈する
- 構築したデータモデルが分析目的の用を足すものか、分析結果から検証する
- データモデルを展開する
- 実運用し、意思決定の役に立てる


コメント